Как читать трейс
Трейс - это дерево вызовов, которое описывает логику работы, отображает ошибки и время выполнения операций. Каждый узел дерева называется спан или observation - он соответствует определенному шагу или событию в работе агента.
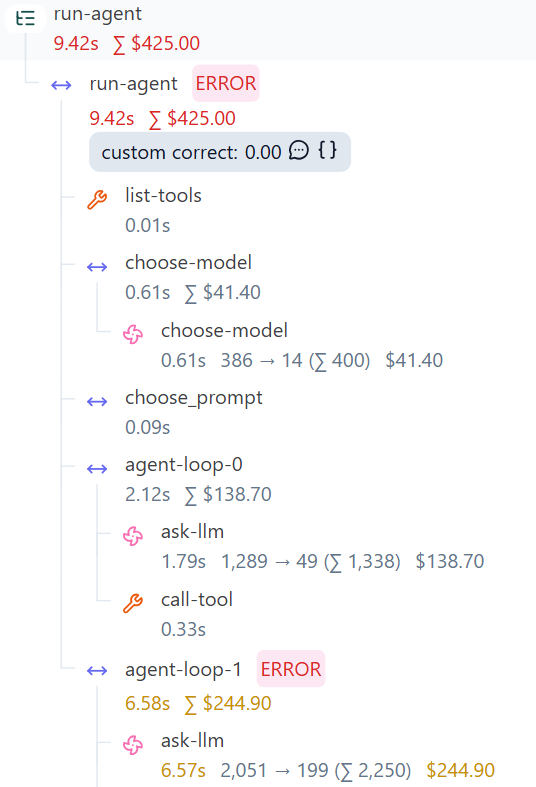
- Трейс читается сверху вниз - от наиболее ранних к наиболее поздним событиям
- На скриншоте мы видим спаны:
run-agent,list-tools,choose-modelи т.д. - Самый первый спан
run-agentназываюткорневымилиroot спаном - Спаны вложены друг в друга, образуя иерархию. Например, если функция А вызвала функцию Б, то спан для Б будет вложен в А. Говорят, что спан Б является
дочернимдля А. Или что Б являетсяродительскимдля А. - Рядом с каждым спаном отображено время выполнения шага в секундах, например
9.42s. Это позволяет проводить диагностику производительности. - Ошибки (необработанные исключения) отображаются в трейсе красным маркером
ERROR - У каждого спана есть иконка, соответствующая типу спана. Список доступных типов
- Выбрав спан можно изучить более детальну информацию...
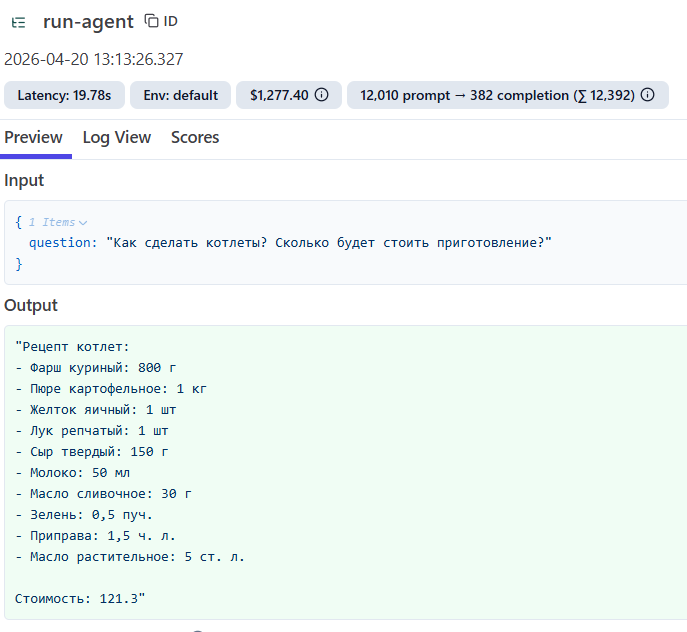
- У каждого спана есть детали, в которых отображается метаинформация и точное время события
- В спане так же могут быть зафиксированы входящие
inputи исходящиеoutputданные шага. Например, запрос и ответ от LLM. Это очень полезно для диагностики работы агента.
В общем случае, для диагностики дефекта:
- Смотрим, есть ли в спане явные ошибки
ERRORи изучаем их. - Если явных ошибок нет - находим спан с результатом (часто последний)
- Изучаем
inputспана, чтобы понять - насколько корректную информацию мы получили на вход. Если на вход была подана неверная информация - идем выше по дереву, чтобы найти источник некорректных данных - Изучаем
outputспана, чтобы убедиться, что внешняя система или шаг алгоритма ответили правильно.