LLM-as-a-judge
Давайте научимся автоматические оценивать качество ответов агента (Evaluation), с помощью другой LLM.
Документация:
Создайте подключение к LLM в проекте Langfuse
В вашем проекте Langfuse зайдите в раздел
Settings \ LLM Connections
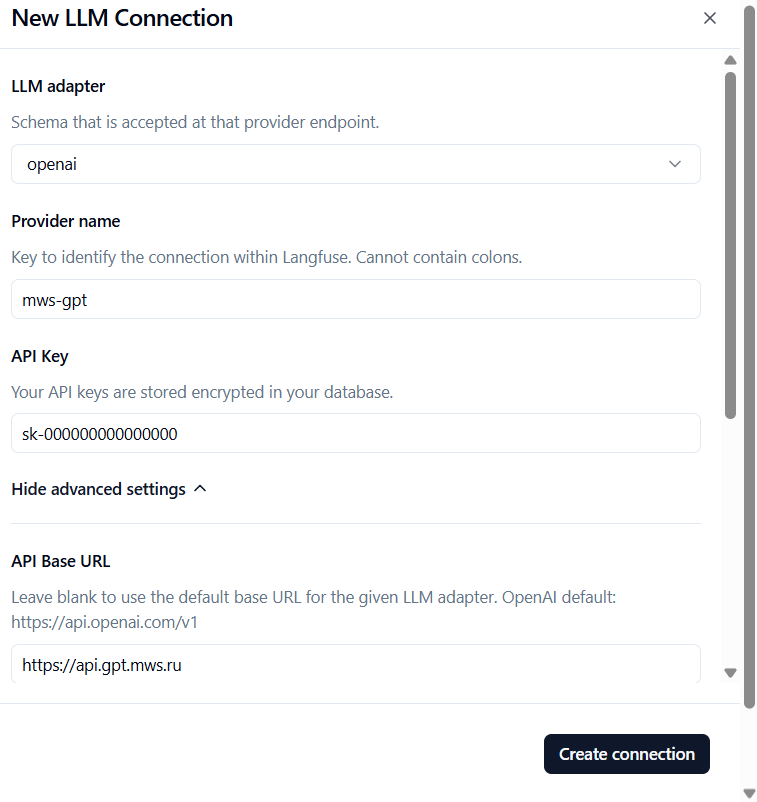
Создайте новое подключение к LLM - нажмите Add LLM Connection, укажите:
- LLM adapter:
openai - Provider name:
mws-gpt - API key:
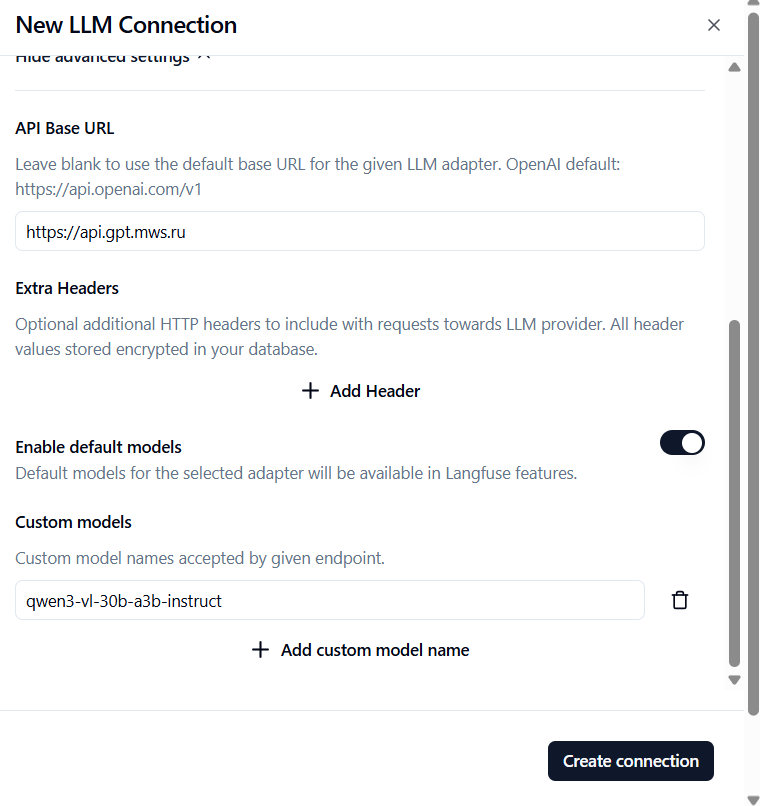
sk-II8bOcxALbJSOXL8epeCmQ - API Base URL:
https://api.gpt.mws.ru - Custom models:
qwen3-vl-30b-a3b-instruct
Создайте ШАБЛОН evaluator'а
Для этого в вашем проекте Langfuse перейдите в раздел LLM-as-a-judge
Нажмите + Set up evaluator и выберите + Create Custom Evaluator (внизу справа кнопка)
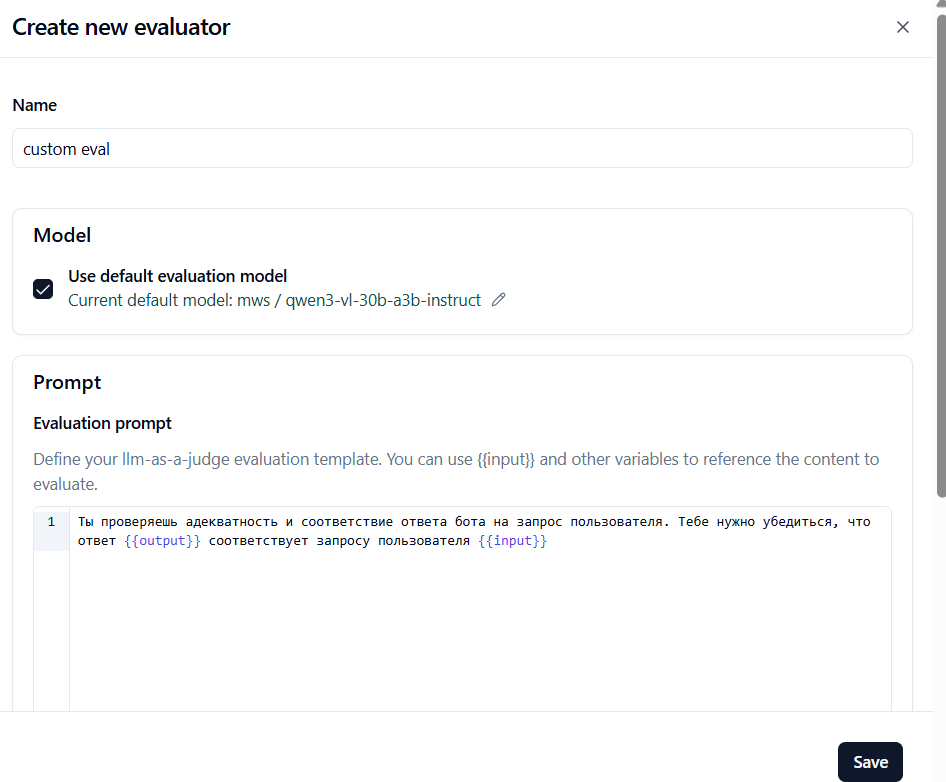
Выберите имя для шаблона, например custom eval и введите примерно такой текст в Evaluation prompt:
Ты проверяешь адекватность и соответствие ответа бота на запрос пользователя. Тебе нужно убедиться, что ответ {{output}} соответствует запросу пользователя {{input}}
Примечание: Создание шаблона может подвисать (баг langfuse). Перезагрузите страницу, скорее всего шаблон создался
Создайте экземпляр evaluator'а из шаблона
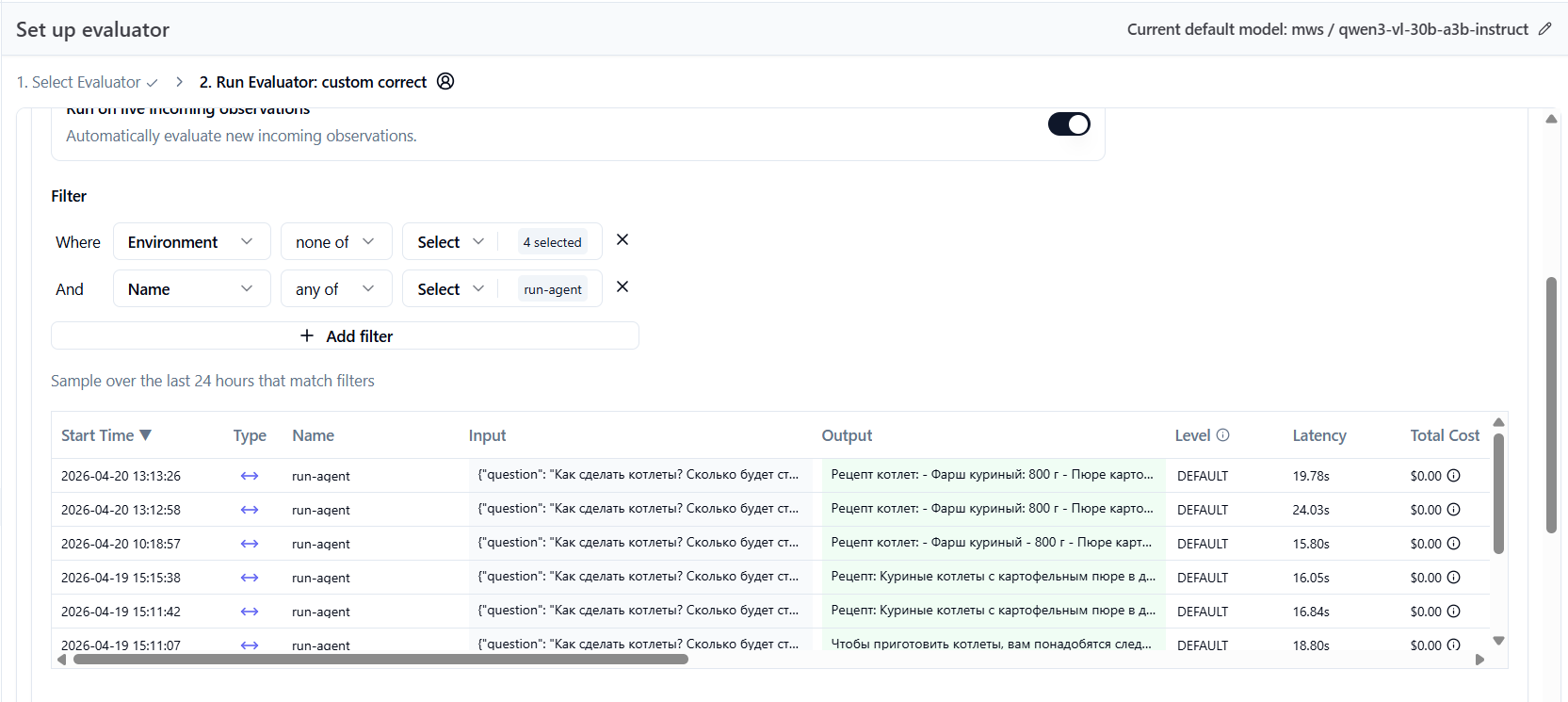
Для этого снова нажмите + Set up evaluator и выберите из списка ранее созданный custom eval в разделе Custom evaluators
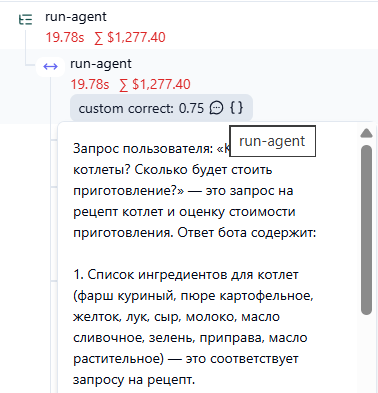
Добавьте в фильтр условие Name any of run-agent (чтобы проверка работала только для финалного запроса)
Уберите из фильтра TYPE
Если фильтр выбран верно - вы увидите список подходящих спанов run-agent в таблице.
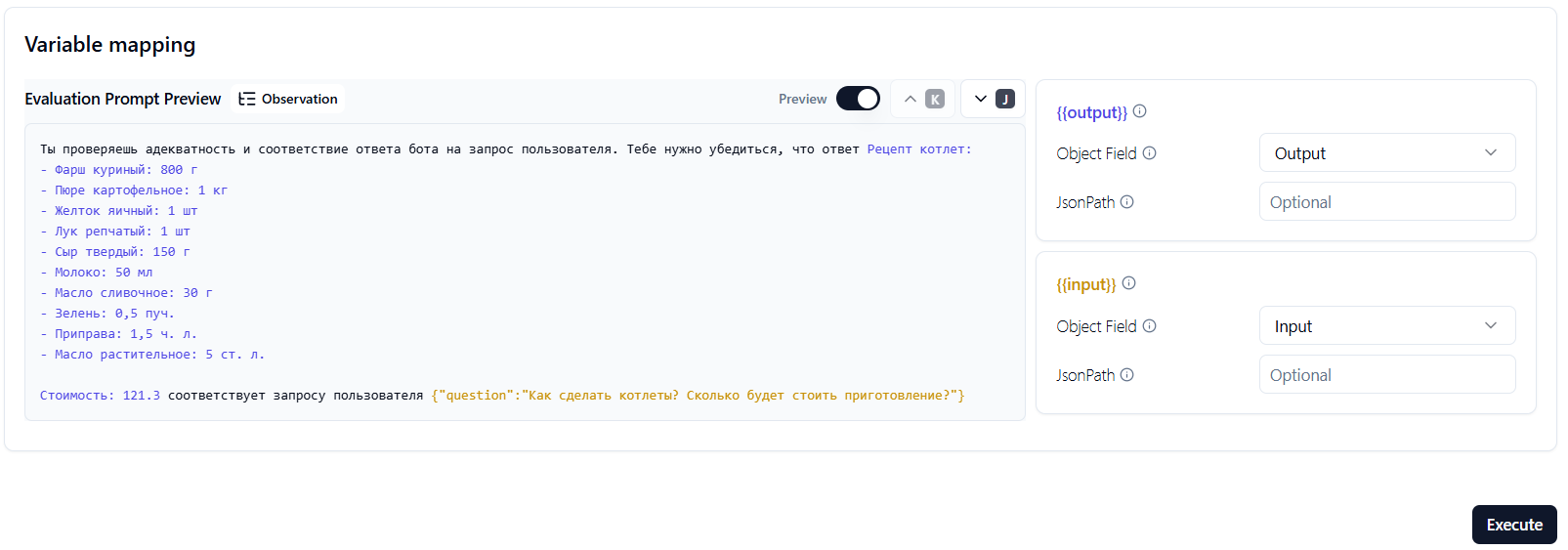
Настройте маппинг секций {{output}} и {{input}} - установите Object Field в Output и Input соответственно
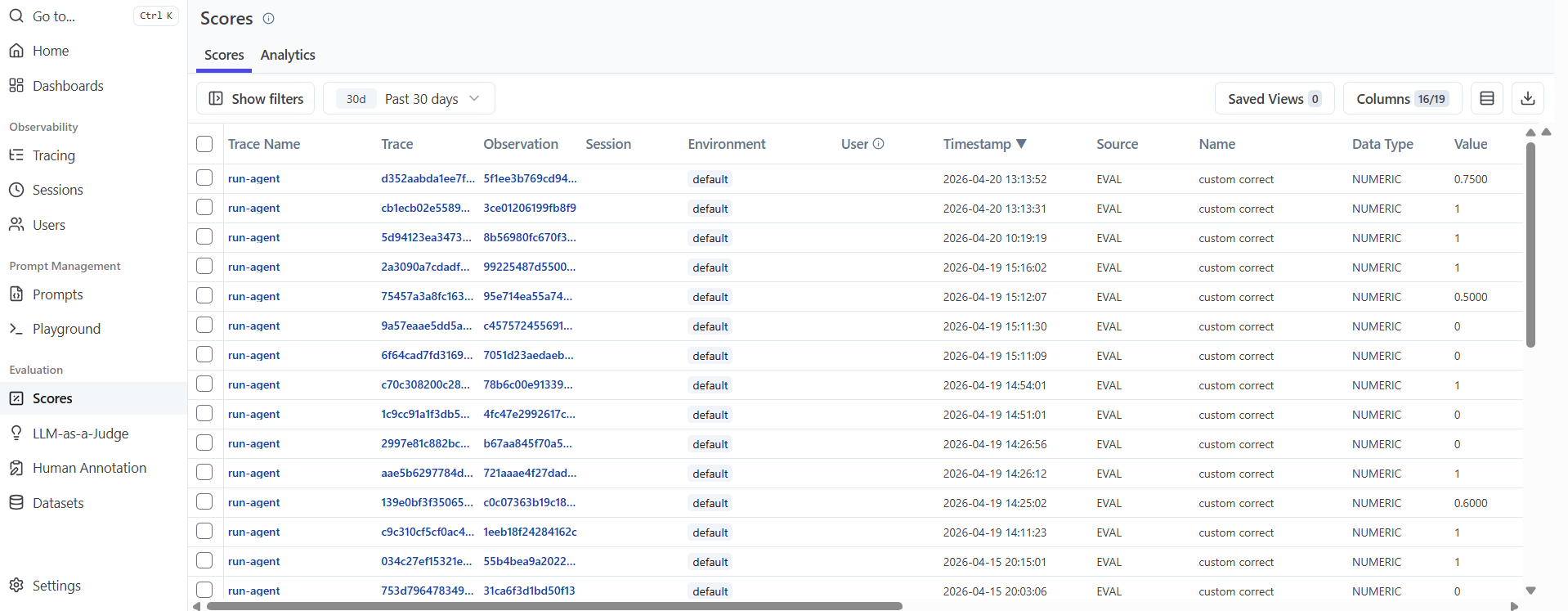
Сделайте запросы к агенту
Сделайте несколько запросов к агенту
Задача
Добиться появления в трейсах Langfuse у спана run-agent оценки качества и ее обоснования